Les erreurs HTTP 429 se produisent lorsque la consommation sur un conteneur est supérieure au débit provisionné.
Avant tout de chose, est-ce grave ?
Tout dépend de la situation, la finalité d’une erreur 429 est que la requête n’a pas été exécutée, cela peut être problématique dans des contextes où la cohérence des données est importante (ex: ajout d’un profil utilisateur), mais moins si elle ne l’est pas (ex: une vue sur une vidéo durant un pic de trafic de quelques secondes).
Les réflexes à adopter
Optimiser les requêtes
Optimiser les RU
Le RU (unité de requête/request unit) est l’unité de devise du débit. Elle est calculée via différents facteurs qui sont très bien détaillés sur le site de Microsoft.
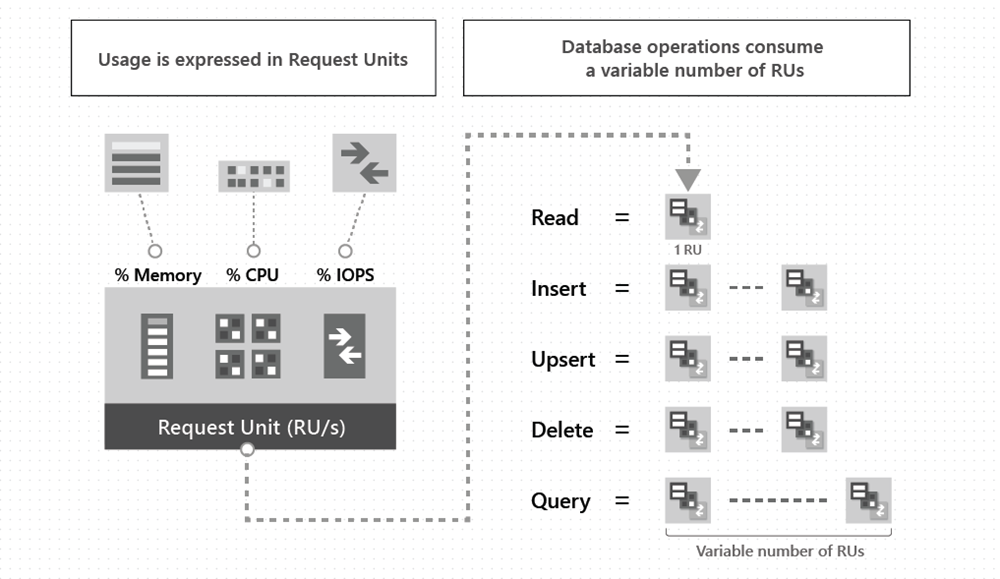
Même en connaissant tout les facteurs il faut prendre en compte que la formule de calcul reste chez Microsoft, de ce fait il est très difficile de prédire à l’avance combien précisément une requête consomme en RU.
Néanmoins il est possible de connaître la consommation d’une requête après l’avoir exécutée et d’adapter en fonction en examinant l’en-tête x-ms-request-charge de la réponse.
Cette donnée est aussi disponible via le portail lors de l’exécution d’une requête:
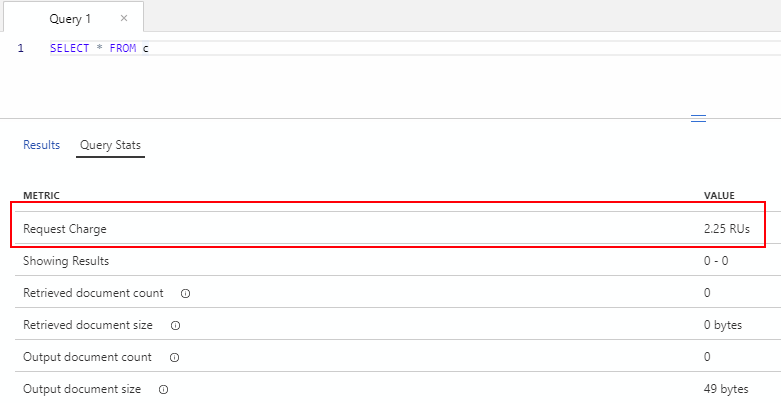
Et directement via le SDK au travers de la propriété RequestCharge.
|
|
La fréquence
La fréquence de lancement des requêtes est primordiale et aussi la plus compliquée à déterminer (nous n’allons ici pas parler des Bulk insert/update qui feront l’objet d’un autre article).
Supposons le cas où vous ayez 50 requêtes à 10 RU chacune, sur une provision à 400 RU/s le lancement de toutes les requêtes en parallèle provoquera des erreurs 429.
Deux solutions sont possibles : augmenter temporairement le provisionnement ou lisser les requêtes dans le temps (par seconde).
Nous allons nous attarder sur la deuxième solution: le lissage dans le temps n’a pas pour but de séquentialiser 1 à 1 nos requêtes, ou faire 1 requête par seconde, ça serait une catastrophe niveau performance et nous perdrions tout l’intérêt de la puissance du parallélisme que nous offre Cosmos DB, l’objectif sera de trouver le bon compromis entre performance et usage selon notre contexte et nos ressources.
Il faudra donc se poser la question suivante:
Bien évidemment il n’y a pas de réponse universelle à cette question, tout dépend de votre contexte (ressources / usages / fréquences…).
Mais une fois la réponse trouvée ou supposément trouvée voici une méthode d’extension que vous pouvez retrouver sur mon gist qui permet de limiter le nombre de tâche en parallèle de manière temporisée et ainsi répondre par exemple au besoin: “je veux X traitements toutes les secondes”.
|
|
Recommencer
La solution la plus simple et courante est tout simplement de relancer la requête.
En effet en partant du principe que le conteneur n’est pas sous-provisionné, des erreurs 429 peuvent arriver occasionnellement lors d’une activité à fort trafic.
Dans cette situation rien ne sert de sur-dimensionner le conteneur (et ainsi payer plus) pour éviter un problème qui intervient seulement quelques secondes dans la journée.
L’erreur HTTP 429 est accompagnée de l’en-tête x-ms-retry-after-ms qui indique dans combien de temps il sera possible de relancer la requête.
Heureusement cette logique de relancement est déjà gérée par le SDK via la propriété MaxRetryAttemptsOnRateLimitedRequests
|
|
En théorie oui… mais dans la quasi-totalité des cas c’est une très mauvaise idée. En effet créer un très grand nombre de tentative :
- augmente le délai d’exécution des requêtes (429 -> attendre 100ms -> 429 -> attendre 100ms -> […] -> OK)
- peut provoquer des effets de bord très graves sur l’application (lenteurs, threads bloqués, timeout…)
- fait office de cache misère et ainsi masque le fait que votre conteneur est sous-provisionné
Concernant le nombre à mettre, il n’y a pas de “nombre magique” cela est à adapter en fonction du besoin (Microsoft recommande néanmoins par exemple de passer cette valeur à 30 durant l’insertion d’un grand nombre d’entité).
AutoPilot
En preview à l’écriture de cet article, Cosmos AutoPilot permet de mettre à l’échelle automatiquement le conteneur selon une plage de RU donnée.
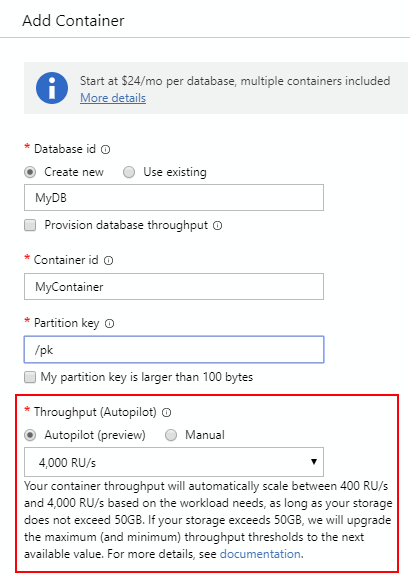
Il faut néanmoins prendre en compte plusieurs aspects de AutoPilot:
- Il possède sa propre tarification (plus élevée que le provisionné)
- Il n’empêche pas les 429 mais les limites fortement (dans l’illustration si vous dépassé les 4000 RU/s les requêtes passeront en 429)
- A l’écriture de l’article il n’est pas encore possible de provisionner un conteneur en AutoPilot via le SDK (mais ceci est prévu)
Augmenter le provisionnement
Si malgré toutes les actions précédentes des erreurs 429 apparaissent toujours et sont problématiques, alors cela signifie simplement que votre conteneur est sous provisionnée par rapport à votre besoin.
Pour aider à choisir le provisionnement adapté Microsoft met à disposition une calculatrice à capacité: https://cosmos.azure.com/capacitycalculator/.
Conclusion
Les erreurs HTTP 429 ne posent pas de problèmes tant qu’elles sont gérées et restent occasionnelles.
Elles doivent avant toute chose être un point d’alerte pour se poser des questions sur les performances du code/requêtes et le provisionnement des conteneurs.
Sources
Repository
Documentation
- https://docs.microsoft.com/en-us/azure/cosmos-db/performance-tips
- https://docs.microsoft.com/en-us/azure/cosmos-db/provision-throughput-autopilot
- https://docs.microsoft.com/en-us/azure/cosmos-db/autopilot-faq
- https://docs.microsoft.com/en-us/azure/cosmos-db/optimize-cost-queries
- https://docs.microsoft.com/en-us/azure/cosmos-db/request-units
- https://cosmos.azure.com/capacitycalculator/
